
Introduction
In the ever-evolving landscape of data architecture, the surge of innovative concepts and methodologies has been nothing short of revolutionary. Amidst this transformation, two models have emerged as frontrunners in addressing the complexities of modern data management: Data Mesh and Data Fabric. These paradigms are not just buzzwords; they represent a fundamental shift in how organizations approach data engineering and architecture, paving the way for advanced applications in artificial intelligence and generative AI.
Data Mesh and Data Fabric, though distinct in their architecture and philosophy, share a common goal: to enable more agile, efficient, and scalable data handling in large organizations. As we delve deeper into these models, it becomes clear that they are more than mere technical solutions; they are strategic frameworks that redefine the role of data within enterprises. This blog aims to unravel these complex models, providing tech professionals, architects and Data Analytics leaderships with a comprehensive understanding of their principles, applications, and impact on the future of data engineering.
In the following sections, I will explore each model in detail, compare their strengths and weaknesses, and provide practical recommendations for organizations contemplating their adoption. Whether you are a seasoned data professional or just beginning to navigate the vast ocean of data architecture, this post will equip you with the knowledge to understand and leverage the potential of Data Mesh and Data Fabric in your own data journey.
Section 1: Understanding Data Mesh
In the realm of data engineering, the term “Data Mesh” has rapidly gained traction, heralding a paradigm shift in how data is conceptualized and managed. This innovative model is not just a technical framework; it represents a philosophical evolution in data architecture, one that is particularly aligned with the demands of generative AI and large-scale data operations.
The Concept of Data Mesh
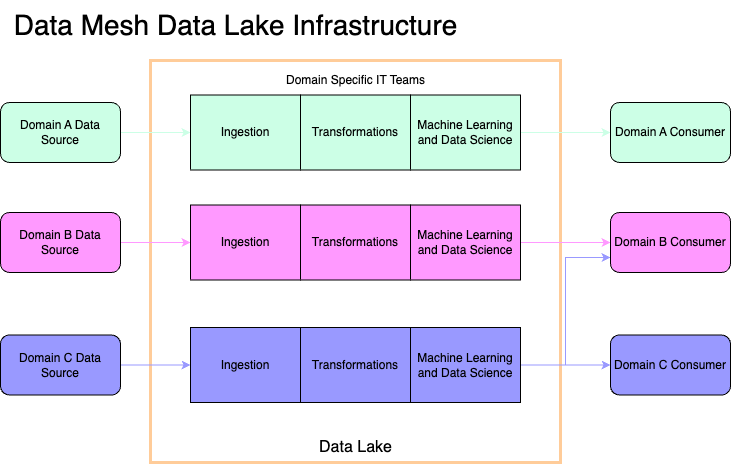
source: phdata.io
Data Mesh is grounded in the idea of decentralized data ownership and architecture. Unlike traditional centralized data lakes or warehouses, where data management is the prerogative of a specialized team, Data Mesh advocates for a more democratized approach. In this model, data is treated as a product, with domain-specific teams responsible for their own data as a product owner would be. This shift empowers teams to manage and deliver data in a way that is more aligned with their specific needs, fostering agility and innovation.
Key Components and Principles
Data Mesh is built on four fundamental principles:

- Domain-oriented decentralized data ownership and architecture: Data is managed by domain-specific teams who understand its context and nuances.
- Data as a product: Treating data as a product emphasizes quality, usability, and user-centric design.
- Self-serve data infrastructure as a platform: This principle ensures that teams have easy access to data tools and platforms, reducing dependencies and bottlenecks.
- Federated computational governance: Establishes guidelines and governance models that balance autonomy with coherence across different data domains.
Relevance in Today’s AI and Data-Driven World
As organizations grapple with the complexities of big data and the demands of artificial intelligence, the Data Mesh model offers a compelling solution. Its decentralized nature aligns well with the needs of generative AI applications, which often require diverse, domain-specific datasets. By enabling domain experts to manage and curate their data, Data Mesh ensures that AI models are fed with high-quality, relevant data, accelerating innovation and improving outcomes.
Section 2: Exploring Data Fabric
Data Fabric is another transformative concept in the realm of data architecture, designed to address the growing complexities and integration challenges in modern data environments. This model offers a unique solution, particularly in the context of artificial intelligence and the vast data ecosystems that drive it.
What is Data Fabric?
Data Fabric refers to an integrated layer of data and connecting processes that provides a consistent and comprehensive view across a wide range of data sources. It is designed to seamlessly connect different data types, sources, and locations, whether they are on-premises or in various cloud environments. The goal of Data Fabric is to provide an agile, flexible, and scalable infrastructure that can support a wide range of data operations and analytics.
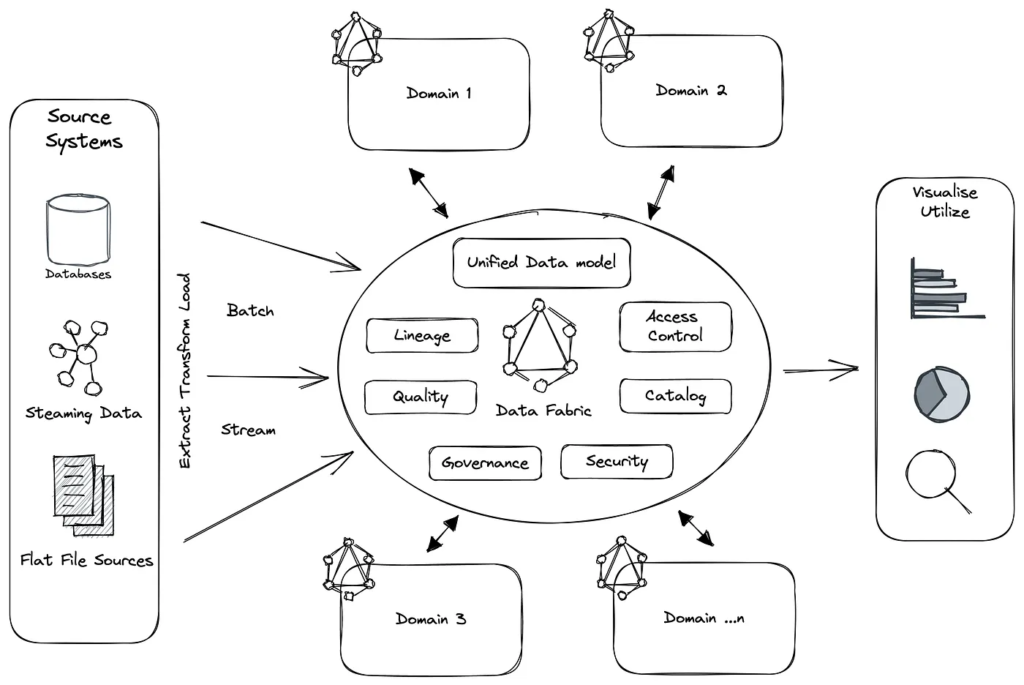
Source: medium.com
Core Features and Implementation
Key characteristics of Data Fabric include:
- Integrated Data Management: Combining data integration, preparation, and analytics to provide a unified data handling experience.
- Automated Data Discovery and Governance: Utilizing AI and machine learning for metadata management, ensuring data quality and compliance.
- Dynamic Data Access and Delivery: Facilitating real-time access to data across the organization, regardless of its original format or location.
Role in Simplifying Data Integration and Management
Data Fabric’s ability to connect disparate data sources and types simplifies the data integration process, making it an ideal architecture for complex, multi-cloud, and hybrid environments. Its automated and AI-driven features are particularly useful in artificial intelligence applications, where the diversity and volume of data require efficient management and integration capabilities.
Section 3: Comparison – Data Mesh vs. Data Fabric
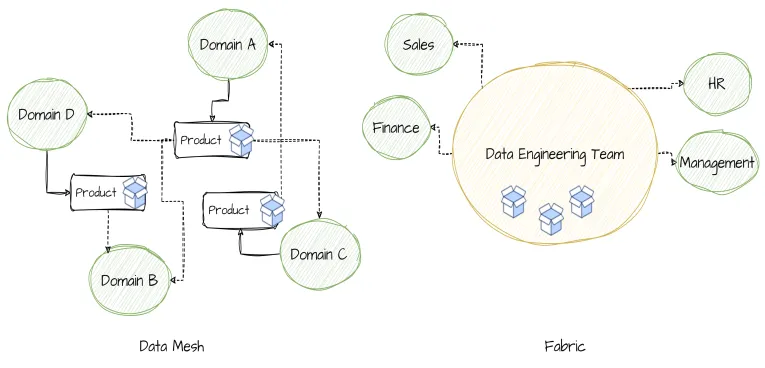
source: medium.com
While Data Mesh and Data Fabric are both innovative approaches to data architecture, they differ significantly in structure, scalability, and complexity. Understanding these differences is crucial for organizations deciding which model to adopt. Below is a table that outlines the key aspects of each model:
| Aspect | Data Mesh | Data Fabric |
|---|---|---|
| Structure | Decentralized, domain-oriented | Integrated, unified layer |
| Data Management | Decentralized ownership, with data treated as a product | Centralized management with integrated data operations |
| Scalability | Highly scalable, suited for large, distributed teams | Flexible and scalable, adapts well to various data volumes and sources |
| Complexity | Requires cultural shift and buy-in from multiple teams | Technically complex but offers streamlined data integration |
| Best Suited For | Large organizations with mature data cultures and multiple independent teams | Enterprises needing to integrate diverse data sources and types |
Pros and Cons of Each Model
Data Mesh
- Pros: Empowers domain experts, enhances agility, and fosters innovation.
- Cons: Can be challenging to implement in organizations without a strong data culture; requires significant coordination across teams.
Data Fabric
- Pros: Simplifies data integration, leverages AI for governance and management, and provides a unified view of data.
- Cons: Can be technically complex to set up and may require significant investment in technology and training.
Section 4: Recommendations for Organizations
Selecting the right data architecture model – Data Mesh or Data Fabric – is a critical decision for any organization looking to optimize its data strategy. Here are some recommendations to guide this decision-making process:
When to Choose Data Mesh
- For Organizations with Distributed Data Teams: Data Mesh works best in environments where domain-specific teams have the autonomy and capability to manage their data independently.
- Mature Data Cultures: It’s well-suited for organizations that already have a strong data culture and are familiar with concepts like data as a product.
- Scalability Needs: Ideal for organizations that are scaling rapidly and need to decentralize data management to maintain agility.
When to Choose Data Fabric
- Complex, Diverse Data Environments: Organizations with a wide range of data sources and types, including multi-cloud and hybrid environments, will benefit from Data Fabric’s integrative approach.
- AI and Advanced Analytics Focus: If the primary goal is to leverage data for AI and analytics, Data Fabric’s unified view and AI-driven governance can be extremely beneficial.
- Need for Streamlined Data Integration: For companies looking to simplify their data integration and management processes, Data Fabric offers a cohesive solution.
The choice between Data Mesh and Data Fabric should be based on an organization’s specific data needs, culture, and future goals. Both models offer unique advantages and can significantly enhance an organization’s data capabilities. It is essential to carefully assess the organizational structure, data strategy, and long-term objectives before making a decision.
I encourage readers to explore more resources and delve deeper into these models to make an informed decision that aligns with their organizational goals.
Conclusion
The journey through the intricate landscapes of Data Mesh and Data Fabric underscores the dynamic and evolving nature of data architecture in the digital age. These models are not mere technical constructs; they represent a paradigm shift in how data is perceived, managed, and utilized in organizations.
Data Mesh, with its decentralized, domain-oriented approach, offers a path to democratize data ownership, fostering a culture where data is treated as a valuable product. This model is particularly suited for large organizations with distributed teams and a mature data culture, ready to embrace a decentralized yet coordinated approach to data management.
On the other hand, Data Fabric provides an integrated, AI-driven infrastructure, ideal for organizations grappling with diverse, complex data ecosystems. Its ability to seamlessly connect disparate data sources and types makes it a powerful tool for enterprises focusing on AI and advanced analytics.
The decision between Data Mesh and Data Fabric should not be taken lightly. It requires a deep understanding of an organization’s current data capabilities, culture, and long-term aspirations. As the field of data engineering continues to evolve, driven by advancements in artificial intelligence and generative AI, the choice of the right data architecture model becomes increasingly crucial.
I hope this exploration into Data Mesh and Data Fabric has provided valuable insights and guidance for tech professionals, architects and Data Analytics leaders navigating the vast and complex world of data architecture. The future of data management is bright, and these models stand at the forefront, ready to lead organizations into a new era of data-driven innovation.
If you would like to connect with me to have in dept conversation about this topic please get in touch here or via Linkedin.
Here are some resources that provide detailed guidance on implementing Data Mesh and Data Fabric architectures:
For Implementing Data Mesh:
- “Data Mesh From an Engineering Perspective“
- Comprehensive guide on data mesh architecture and implementing recommendation
- Read more
- “Data Mesh Setup and Implementation – An Ultimate Guide” at Atlan.com:
- This guide outlines the primary steps for setting up Data Mesh architecture, including treating data as a product, mapping domain ownership, building a self-serve data infrastructure, and ensuring federated governance.
- Read more
For Implementing Data Fabric:
- “How to Implement Data Fabric: A Scalable & Secure Solution” at Atlan.com:
- This comprehensive guide outlines eight steps to implement Data Fabric, including developing a Data Fabric architecture, implementing data governance, building a cross-functional data team, and monitoring, optimizing, and scaling the system.
- Read more
- “How to Build a Practical Data Fabric at Scale” at AtScale:
- This article discusses the key technologies within a data fabric, including an augmented data catalog, knowledge graph, and data preparation & delivery layer, along with best practices for implementing a data fabric.
- Read more